

Order from chaos
Building machine learning or AI solutions in the wild is difficult. Besides the uncertainty involved, convincing your business stakeholders to invest in your solution can be extremely difficult. On top of this, there’s an added layer of complexity when you are attempting this in a regulated industry such as banking or pharmaceuticals. I’ve taken the liberty of mapping out how I approach it as a data science lead working in financial services.
The method focuses on six core areas: Business Capture, AI Problem Framing, Data Strategy, AI System Design, Feasibility Assessment & Performance Evaluation.
It is best approached starting with Business Capture then working through the remainder of the sections as you build your prototype solution.
Definition: I’m defining a prototype here as a solution you build that operates at a small scale to prove the concept.
Advantages of using this method:
- An upfront focuses on driving business value.
- Ability to identify opportunities for investment in AI/ML solutions with Value vs. Feasibility assessment.
- An audit trail for the data sources & solution designs.
- A framework for translating business problems into ML/AI solutions.
- A reference design document for your convenience and the engineers that will work on scaling your solution.
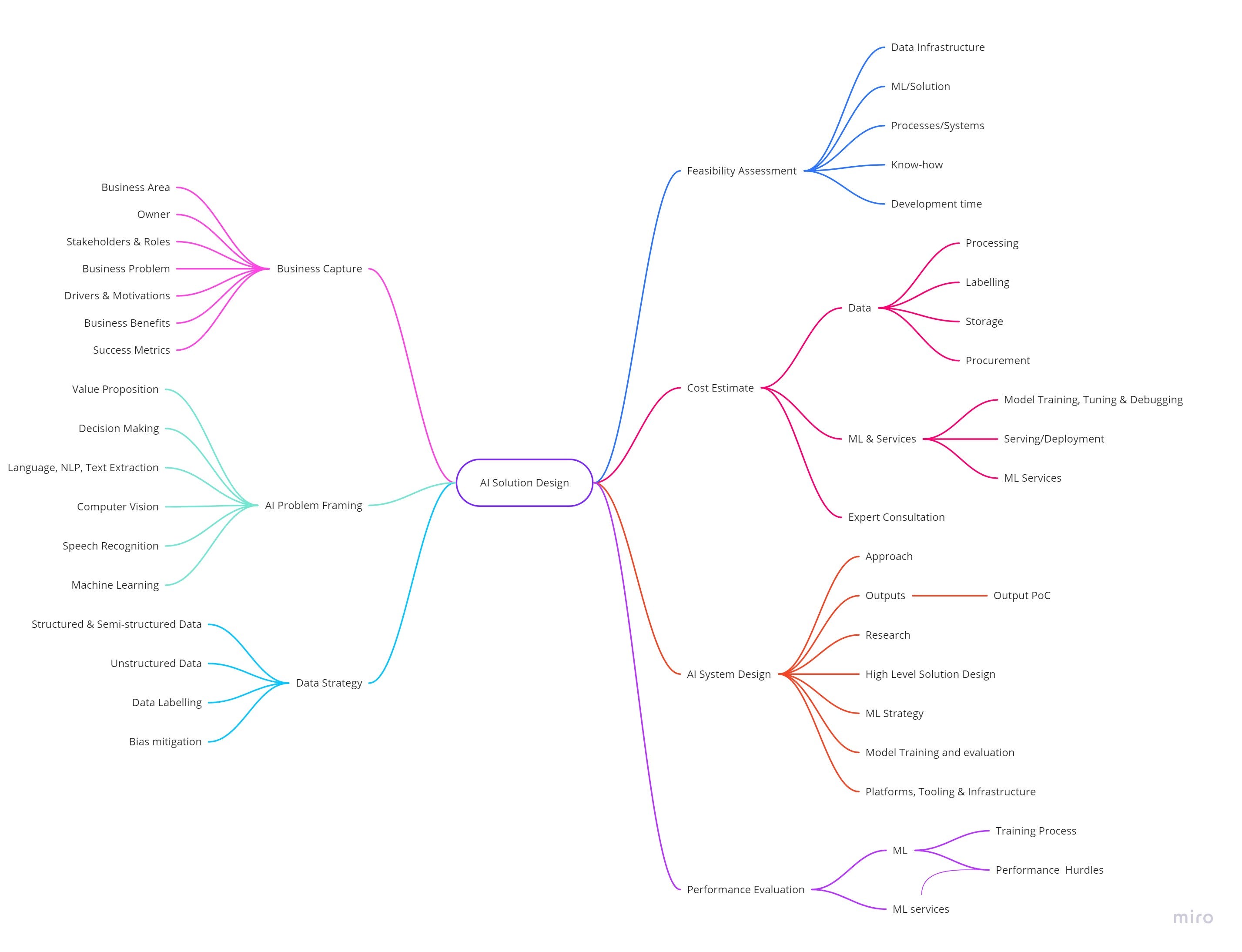
Business Capture
In the business capture phase, you work with your business SME or analyst to frame your business problems. Here are some guidelines for this:
- Business Area & Owner: Take these down as a point of reference, you’ll want to know who would potentially fund a full-scale deployment if your lab were successful.
- Stakeholders and their roles: You want to make a note of who the SME contacts are, what their role or title is, who the analysts are, the data scientists, sponsors etc.
- Problem: Write out the business problem that requires solving, you should get an understanding of this by speaking to your business SME. If the problem appears too complicated, break it down into simpler subproblems and address them separately. Consider answering the following questions: What is driving the change? Who owns the processes? What does a successful solution look like?
- Business benefit: You will estimate the benefit to the business if your solution was to be put in place. Initially, this will be a “back of the envelope” calculation based on the best possible outcomes. You’ll refine this later once the prototype has been built. You’ll want to express this business benefit quantitatively and qualitatively.
AI Problem Framing
Once you have captured your business problem, you can attempt to frame it in terms of AI&ML at a high level.
- Value Proposition: Try to understand who the end-user is, what their objectives are, and how they would benefit from machine learning or AI.
- Decision Making: Intelligent systems can be effective in making decisions. Scope out the decisions your system is making or supplementing, the scale and the frequency. In regulated industries like banking, there are often constraints on “black box” models. So, you will need to understand how interpretable the decision-making process needs to be too.
- ML Services: Your intelligent solution might require you to leverage a combination of ML or AI services provided by a cloud platform or ML PaaS. It’s a useful exercise to scope these out at a high level and decide what they could potentially be. Broadly speaking, ML services fall into the following categories: Language, NLP and text Extraction, Computer vision, and Speech recognition.
- Machine Learning: Not all solutions will require you to build a bespoke machine learning model. You should assess whether you will need to do this or not. You should note that having to build your own bespoke ML solution is often more complex than leveraging ML services.
Data Strategy
Data is the petrol to your machine learning engine, so it is important that you capture your data requirements in detail. Initially consider your requirements for training and inference. If you’re training a machine learning model, what features might be predictive? If you’re just doing inference, what data is required? For example, if you’re building an ID verification engine you might need some photo IDs, you need to know how you will capture this data.
Data management & procurement
You should consider your approach to data management and procurement here too.
Are you using structured/semi-structured data, unstructured data, or both?
There are different requirements for dealing with structured and semi-structured data vs. unstructured data. The way you store your data, the processing costs, volume available are some of the things to consider.
In industry, there are strict regulations on data and how it is used under GDPR. You will want to have a strategy for complying with these. Capturing whether personal data is being used, the data source, primary contact for the data and how long you plan to store it will assist you in passing the inevitable data audits.
Lastly, you will want to capture your acquisitions costs, data isn’t free, and your value proposition could be massively diminished if it requires expensive data.
Data Labelling
In an industry setting, you might want to take a supervised machine learning approach, but you might not have labelled data. You will want to specify your data labelling strategy here. Are you using a service like AWS’s Mechanical Turk, or will you use unsupervised learning to create your labels?
Bias Mitigation
You need to get an understanding of the bias in your data set and put in place strategies for managing them. Examples of bias are:
- Sponsorship Bias*: Are your data sources from a sponsoring agent? Sponsoring agents tend to suppress data that might be reputationally damaging. For example, data on tobacco’s impact on health is gathered by a cigarette company.
- Self-selection Bias*: A form of selection bias where your data sources are from those that volunteered to provide it. This is most survey data.
*Source: Machine Learning Engineering, Andriy Burkov (2020), pg. 44–47
AI System Design
Scope out the detail of your intelligent application. You should use the Business Capture and AI problem framing exercise to help inform you here. Things to consider are:
- Approach: In writing describe what approach you intend to take to solve your problem. You should have a good idea of what machine learning services you require and whether or not you need to train a model.
- Performance Requirements: What are the performance standards that you expect at a minimum? You should think of this in terms of latency requirements and the performance of any models you build or use on test data. Your performance targets should be in line with your business requirements.
- Outputs: What will your outputs be? Will your intelligent system serve inferences to another app, or will it be used to generate an insights dashboard? This will have implications for the design patterns you choose later.
- Research: You need to get a view of the landscape of apps already out there that might solve your problem. It’s often more efficient to go for an “out of box” solution rather than trying to reinvent the wheel. Another thing to consider is whether the problem you’re trying to tackle is a typical ML use case. There is a lot of uncertainty around the success of ML projects, it helps to know whether this has been solved in the past to give you an idea of your chances of success.
- High-Level Solution Design: Map out your solution design end-to-end. If your solution is cloud-native, keep this at the services level and don’t go into detail yet about your ML pipeline (if you’re training a model). These diagrams are useful for engineers, who may help you scale for production at some point.
- Machine Learning Strategy: If you’re training your own model, list out the models you will try along with a baseline model. It’s worth mentioning the limitations of each model here too. You should also draw out a more detailed machine learning pipeline here including steps for data segregation, data wrangling, feature engineering, model training & evaluation loops etc. You will probably need to loosely define your strategy for monitoring any ML models you train once they go live. Consider the attributes you wish to monitor, how you will set your baseline performance and your monitoring schedule. As a standard, you will probably want to monitor data quality, model quality/performance, model bias drift, and feature attribution.
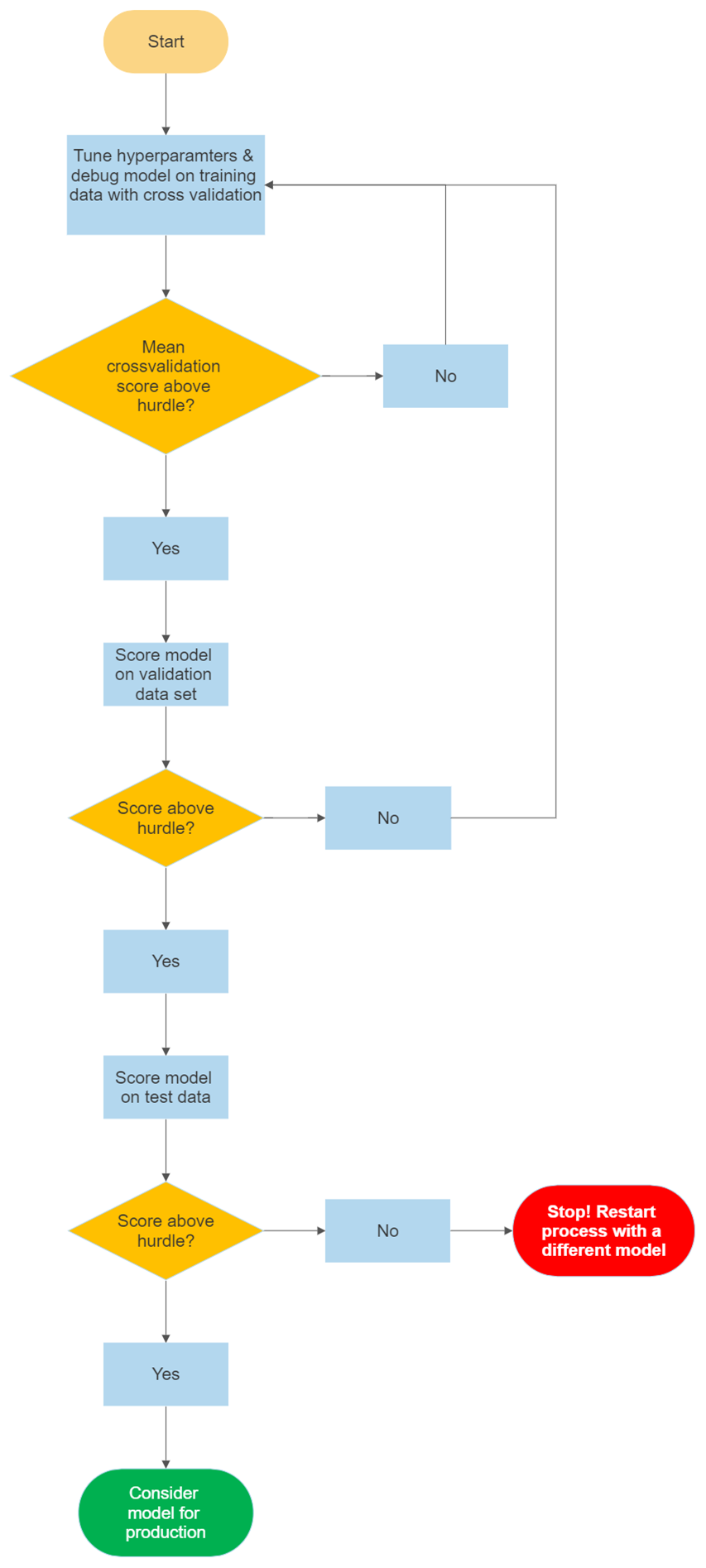
- Model Training & Evaluation: What are your splits for Training, Validation and Test data sets? What strategies will you use to tune your hyperparameters and test your model?
- Platforms, Tooling, and Infrastructure: Think about the services you need and how much they will cost you. If you’re using a cloud platform like AWS, there are a myriad of machine learning services that you can leverage, and you can estimate costs using the AWS calculator tool. Similar options exist for other cloud platforms including, Azure and GCP.
Performance Evaluation
Whether you’re training your own bespoke models or you’re leveraging existing ML services you should be tracking their performance against the requirements you stipulated.
For bespoke machine learning solutions, you should have a scientifically rigorous strategy for evaluating model performance to prevent overfitting and to maximise the chance of your model working properly in production.

Feasibility Assessment
You should remember that your end goal is to build a model that can work in production and add value to your business. Once you have scoped out all the requirements and built the prototype, you will have a better understanding of how feasible your solution is to scale. Things to consider here are:
- Data Infrastructure: Data Access, volume and quality.
- ML/Solution: Technical resources available, existing solutions, knowledge of the solution.
- Processes & Systems: Are there any business process changes, system adjustments, or organisational changes required to implement your solution?
- Know-how: Is the tech and domain knowledge available to you? And how long will it take to upskill your team to meet requirements?
- The solution to live: How long will it take to take your solution to living?
The Initiative for Applied Artificial Intelligence has released a white paper that gives you a method for assessing the feasibility of your intelligent solutions.
Value vs. Feasibility
You should be able to assess the value vs. feasibility of your solution. You want to go for solutions that have high value and high feasibility, very few solutions you design will fit into this category on the outset. You should revisit the initial design to see if you can go for an approach that is higher feasible. If you’re in an organisation that is early in the adoption curve for intelligent applications, you can scope out several of these solutions to see where there are opportunities for you to invest.
Note: you would have estimated the value of your solution in the business capture phase.


- Top Left: Aspirational projects are hard to do at present but have high business value.
- Bottom Left: Trash, relatively low business value and low feasibility.
- Bottom Right: Low hanging fruit, low business value but high feasibility.
- Top Right: Rockets, high business value and high feasibility.
Applying artificial intelligence to solve business problems is difficult. Because of all the moving parts, it is definitely worth standardising your approach as much as possible to make the process more efficient. Feel free to use what is useful for you here and adapt it where you need to.