

Over the past few years, data jobs have proliferated across the world, becoming some of the most sought-after and well-paid jobs. As technology continues to evolve, new jobs are being created to meet business needs. In parallel, the hard skills and technologies required to get these jobs have also ballooned. Such technologies sometimes include unfamiliar names such as “Hadoop”, “MapReduce” or “Blue Prism”, making it a bit hard to keep track of which tool does what, and which is required for what.
In this post, I explore ~9,000 job postings from Glassdoor to understand how three prominent data jobs — Data Analyst, Data Scientist, and Data Engineer — differ in what skills they require: data science domains, specific technologies, and soft skills.
The outline of this blog post is as follows:
- Methodology
- Comparison #1: How do data science domains differ across the three roles?
- Comparison #2: How does the required technology differ across the three roles?
- Comparison #3: How do soft skills differ across the three roles?
- [Bonus] Additional descriptive statistics: How do salaries differ across the three roles? Which companies provide the most used software? Is the technology open source or proprietary?
Methodology
1. Understanding the Data Source
My underlying data comes from recently scraped data from Glassdoor, and made available on Github by the user pickles eat, for three positions:
- Data Analyst, containing ~2,200 job postings.
- Data Scientist, containing ~3,900 job postings.
- Data Engineer, containing ~2,500 job postings.
All three datasets come in .csv files and contain organized information about the job postings, most notably: Job Title, Job Description, Location, Salary Estimate (as a range), Industry and Sector.
For the purposes of this post, I clean two variables: Job Description and Salary Estimate:
- Job Description: I use the tidytext package in R to “tokenize” Job Description; that is, to separate all words within every single job description in order to extract which words appear with the highest frequency. The challenge that presented itself is that a lot of skills are in fact two words. For example: “critical thinking” or “Apache Hadoop” are skills that only make sense if the two words are grouped together, because “critical” or “Apache” as stand-alone words do not mean much. Therefore, I iteratively identified the most frequent collection of words, created a union of these words (e.g., “critical thinking” became “critical thinking”) so that the tidytext package could identify them as stand-alone words. After this cleaning process is complete, I remove the most frequent grammar words (e.g., “and”, “I”, “what”) to obtain a list of the most frequent and relevant words that appear in the “Job Description” variable.
- Salary Estimate: Because these job postings are scraped from Glassdoor, their associated salaries are wide ranges that cannot be easily grouped together. For example, three job postings have these three ranges in the salary estimate variable: (37K-66K), (46K-87K), (51K-88K). If I were to take the lower and upper bound for these three posts, the ensuing range would be too wide (37K-88K). Therefore, I created a lower salary range and upper salary range for each job posting. That is, in the example above, the lower salary range is 37K-51K and the higher salary range is 66K-88K.
After I clean these two variables, the next steps are to categorize and sub-categorize the most frequent words into the following large categories:
- Data Science Domains to understand the actual tasks required of the three roles.
- Technology Skills to understand which programming languages or software are required for the three roles
- Soft Skills
2. Creating a Data Science Domains Taxonomy
I found this figure from Analytics Vidhya very helpful to understand and differentiate between the different “domains” that constitute data science.

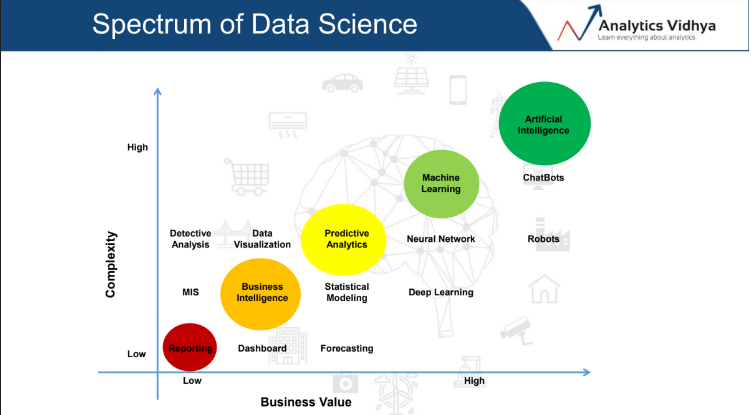
I, therefore, use this categorization to organize words from the job descriptions to fit into the categories above. I also add two other categories that are missing from the figure above ETL (Extract, Transform, Load) and Cloud Computing, as they are both widely used for the Data Engineer role (and to some extent the other roles as well).
See below examples of which words from the job postings datasets are within which category:
- Reporting: reports, financial reporting.
- Business Intelligence: visualization, dashboards, interactive, BI.
- Predictive Analytics: modeling, statistical, forecasting, predictive, models, statistics.
- Machine Learning: ML, deep learning, neural networks.
- Artificial Intelligence: AI, chatbot, natural language processing.
- ETL: mining, warehousing, extract, transform, load.
- Cloud Computing: the cloud.
3. Creating a Data Technology Taxonomy
After creating the data science domains taxonomy, I also identify the most widely used data science programming languages or/and software and categorize them. As a base for recognizing these technologies within the job descriptions of my database, I use a list from this source (written by Angela Stringfellow), which identifies and defines 50 data science tools. After I understand the most widely-used tools, I create categories for them based on my research and understanding. These categories, which I denote as “Purpose”, are as follow:
- Database Management, (e.g., SAP, Oracle Database, MongoDB)
- Data Stream Processing, (e.g., Hadoop, Hive, Kafka, Kinesis)
- Multi-purpose, used to extract, clean, analyze (e.g., Python, R, SQL, alteryx)
- Software Development, (e.g., JavaScript, Docker, Java)
- Cloud Computing, (e.g., Azure, AWS, Google BigQuery)
- Machine Learning / AI, (e.g., TensorFlow, PyTorch, Keras, NLT)
- Statistics, (e.g., SAS, Stata, MATLAB)
- Code Management, (e.g., Github, Jira, Jupyter)
- Data Storage, (e.g., XML, JSON)
- Data Visualization, (e.g., Tableau, Power BI, Looker, Shiny — R)
To better understand how I constructed this taxonomy, have a look at the extract below:


You will notice from the figure above that I also add information about the type of these tools (e.g., programming language vs. software), providers of these tools (e.g., companies, universities or individuals) and their level of access (e.g., open-source / free or proprietary / paid).
Now that the data has been cleaned and that the taxonomies have been created, let’s see what the data actually tells us!
Comparison #1: How do data science domains differ across the three roles?
The figure below presents the distribution of data science domains by role, counted by the words belonging to each category as they appear in the job description of the job postings.


As the figure above shows, a Data Analyst is mostly responsible for reporting, predictive analytics (mostly forecasting), and business intelligence.
By contrast, a Data Scientist is mostly responsible for predictive analytics (e.g., statistical modeling) and machine learning.
Finally, a Data Engineer’s share of work is concentrated in ETL activities and Cloud Computing, in addition to predictive analytics.
This is probably not surprising and what we would except as the main differences between these roles. Let’s now look at which hard skills and technologies are required for these roles.
Comparison #2: How does the required technology differ across the three roles?
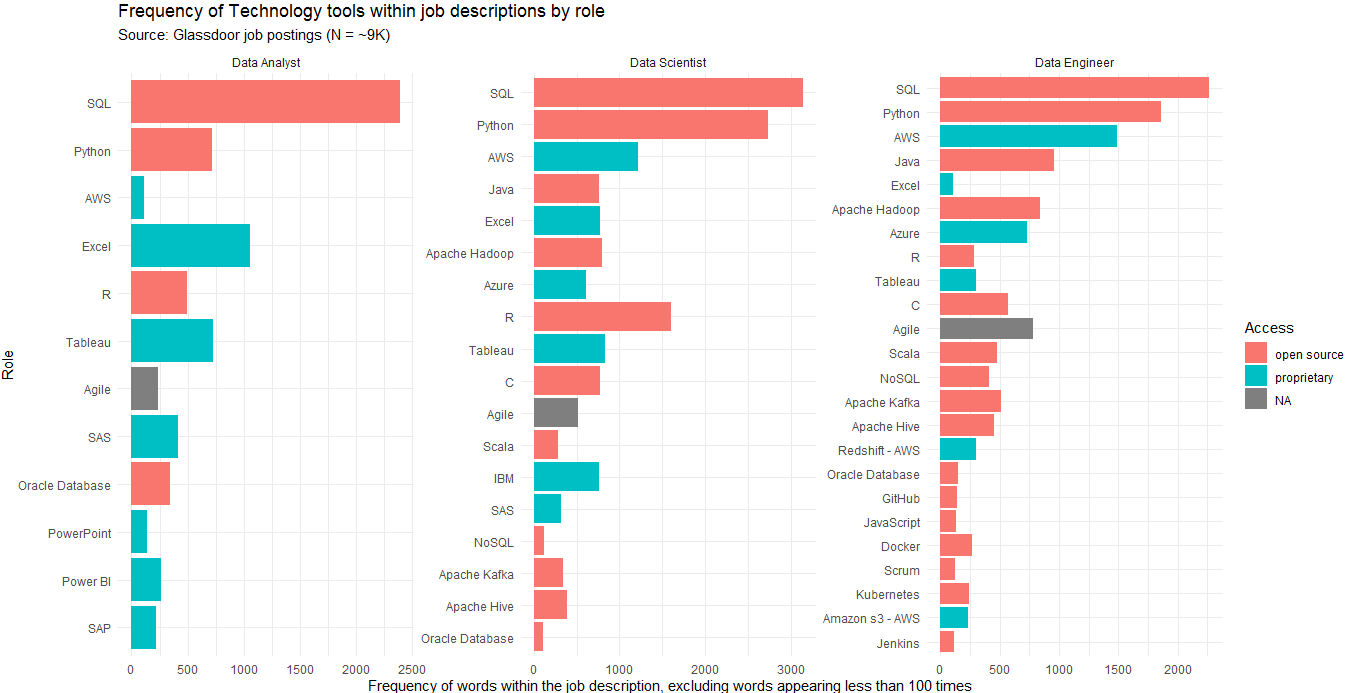
When we look at the most frequent technologies across the three roles (see figure below), we notice the following:
- The top technologies across all three roles are SQL and Python. Both are multi-purpose programming languages that help with extracting, cleaning, and analyzing data. Specifically, SQL is mostly used to fetch data from a database, while Python is used for data preparation, analysis, and visualization.
- The Data Engineer role is required to know a much larger suite of technology tools than the other two roles.
- There is a mix of open source and proprietary tools across the three roles. We’ll explore the distribution of these later.
- There is a large number of tools that might be unfamiliar to a non-industry veteran or a student looking to pick a career. Therefore, the next step is to categorize these technologies to understand their primary purpose.

1. Data Analyst — Technology Distribution
Note that the next few figures have “free-y scales”, meaning that the magnitude of the bar charts across categories is not directly comparable, so make sure you read they scales carefully!
First, let’s look at the Data Analyst position and see the distribution of technology tools by their categories. We can see that the most important tools are the following:
- SQL, Excel, Python and R, all within the multi-purpose category
- Tableau, Power BI and PowerPoint, within the data visualization category
- SAS and SPSS within the statistics category
- Oracle Database, SAP and Salesforce within the database management category

2. Data Scientist — Technology Distribution
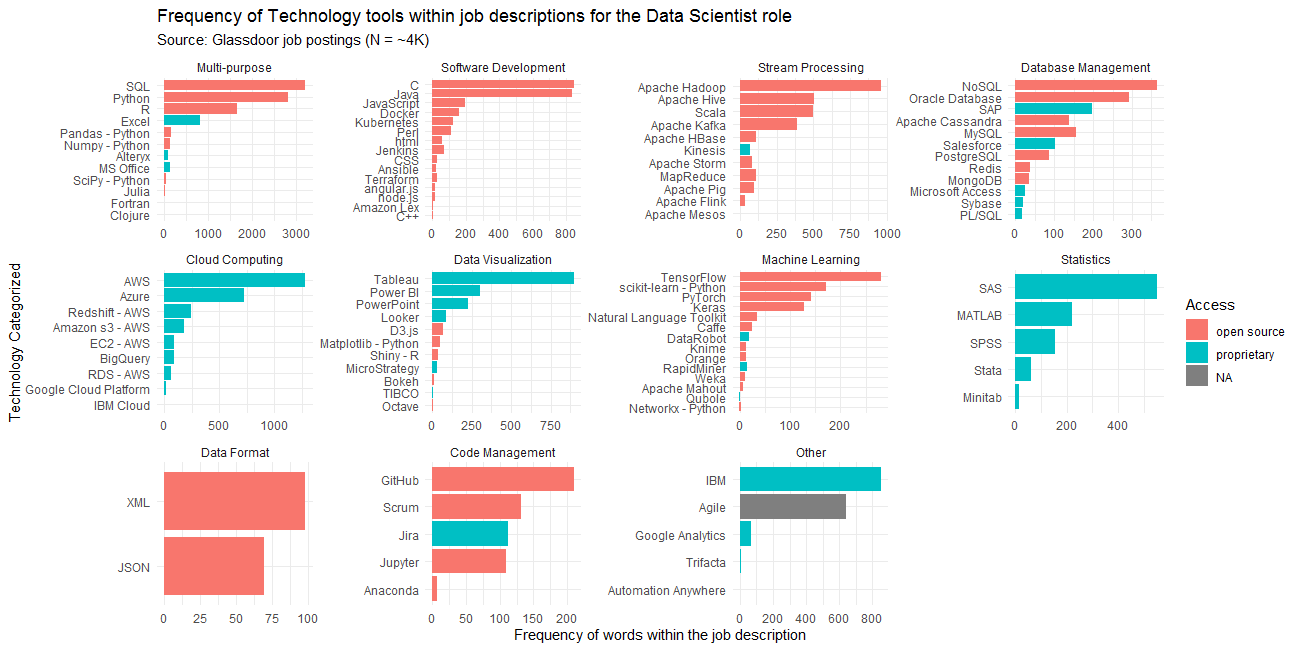
Let’s now look at the Data Scientist role. The most important tools are the following:
- SQL, Python, and R within the multi-purpose category
- Apache tools (especially Hadoop, Hive) and Scala, within stream processing
- AWS (including Redshift, S3, and EC2) and Azure, within the cloud computing category
- IBM tools (though no category is specified)
- C, Java, and Javascript within the software development category
- Tableau and Power BI within the data visualization category
- TensorFlow and scikit-Python within the machine learning category
3. Data Engineer — Technology Distribution
Finally, looking at the Data Engineer role, the most important technology tools are the following:
- SQL, Python, and R within the multi-purpose category
- C, Java, and Javascript within the software development category
- Apache tools (especially Hadoop, Kafka) and Scala, within stream processing
- AWS (including Redshift, S3, and EC2) and Azure, within the cloud computing category
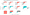
4. Putting it all together
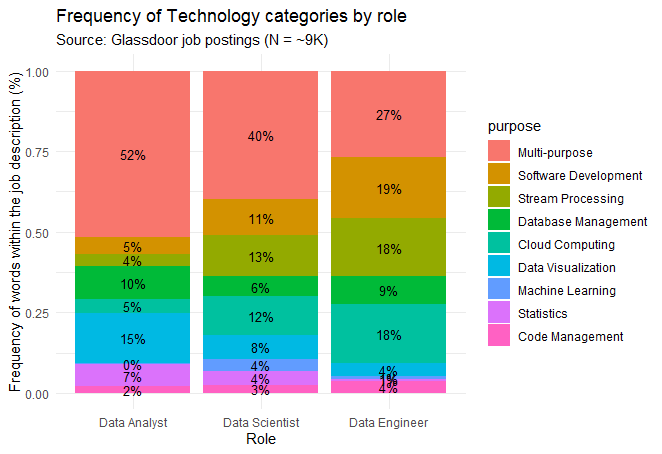
We saw from above that the main tools do not actually differ between these roles, so let’s now look at the break-down of technology categories by role. As the figure below shows, the most important categories per role are:
- For the Data Analyst, general knowledge of multi-purpose tools (e.g., SQL, Python) and data visualization tools
- For both the Data Scientist and Data Engineer, knowledge of stream processing, cloud computing, and software development
It is worth noting that the Data Scientist role seems to be required to know a wider range of technologies than the other two roles.

That was a lot of technology skills! If you are looking to pick a career or will be applying for jobs soon, hopefully, the figures presented so far can help you understand what you need to learn (start with SQL!)
Comparison #3: How do soft skills differ across the three roles?
As we all know, soft skills are of paramount importance in any job. It is not different for these three roles, whose job descriptions reference plenty of soft skills.
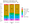
As the figure above shows, the most important and sought-after soft skill across the three roles is communication (both verbal and written). Next, learning (or willingness to learn) is the second most important skill, especially for the Data Scientist and Data Engineer. This makes sense because technologies are continuously being created, so these roles need to quickly adapt. Lastly, we notice that leadership is also a prominent skill across all three roles.
[Bonus] Additional descriptive statistics
1. How is the pay different across the three roles?
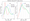
The figure above shows that the Data Scientist role’s salary is higher than the other two roles, while the Data Analyst’s salary is the lowest.
2. How does the technology required to differ by salary ranges?

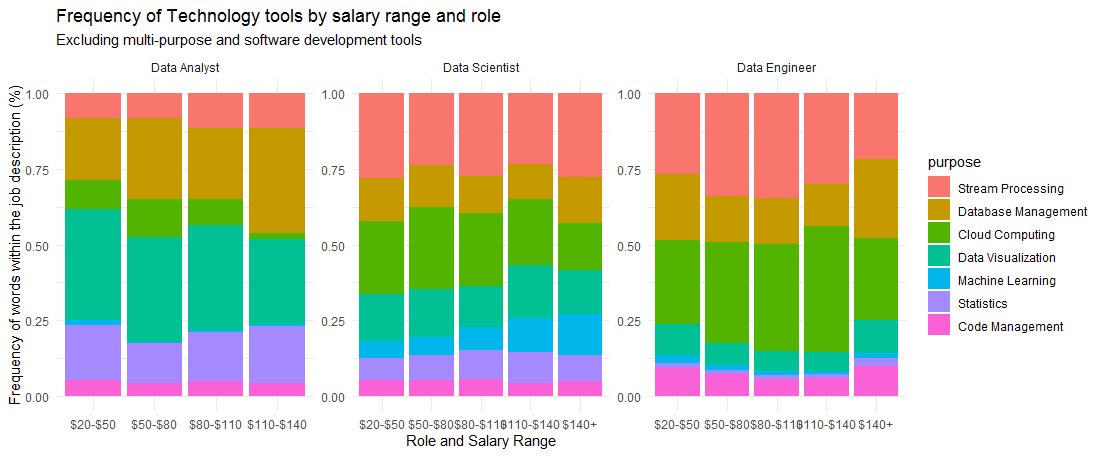
The figure above tells us the following:
- For the Data Analyst, database management and statistics skills are associated with a higher salary range
- For the Data Scientist, machine learning skills are associated with a higher salary range
- For the Data Engineer, stream processing and cloud computing are associated with a higher salary range
3. How does access to the technology tools differ by role?

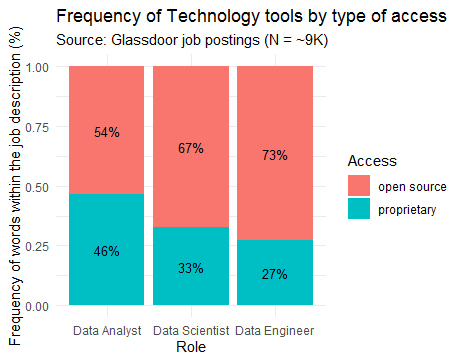
The figure above presents the distribution of technology tools by role and access type. It tells us that the tools for the Data Analyst role are more likely to be packaged as software (and commercialized) than the other roles. This makes sense because the Data Analyst role has been around for longer. In the future, we can also expect the tools for the other two roles to also be packaged and commercialized.
4. How do the technology tools differ by role and provider?

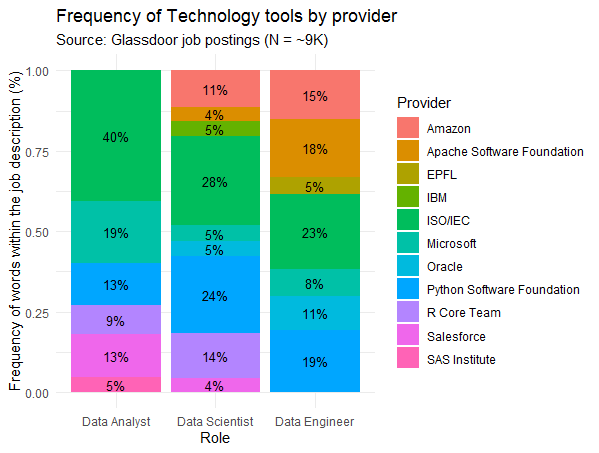
Finally, I was curious to see which providers were most present across the technologies and across the roles. The figure above shows a mix of companies (e.g., Amazon, Microsoft, IBM), non-profit organizations (e.g., ISO/IEC — provider of SQL, Python Software Foundation, R Core Team) and universities (Switzerland’s EPFL, provider of Scala).
Concluding thoughts
Hopefully, this blog post will help you understand what the main difference is between these three data roles. Moreover, if you are looking to break into these as a career, this post hopefully makes it clearer as to which skills you’ll need to develop for each role.
I also hope that the technology taxonomy that I created can be expanded upon and used more widely in labor market analysis. If you have ideas on how we might collaborate to achieve that, please email me at kenza.bouhaj@gmail.com
As always, if you’ve read all the way to here, thank you so much!